Kimya bilmeden kimya yapan yapay zeka
Bonn Üniversitesi’nden araştırmacılar, kimyasal dil modellerinin (CLM) biyokimyasal prensipleri ‘öğrenmekten’ ziyade benzerlik ve istatistiksel korelasyonlara dayalı çıkarımlar yaptığını gösterdi.

Dil modelleri artık doğa bilimlerinde de kullanılıyor. Özellikle kimyada, yeni biyolojik olarak aktif bileşikleri tahmin etmek için başvurulan kimyasal dil modellerinin (CLM’ler) kapsamlı eğitime ihtiyaç duyduğu, ancak eğitim sırasında biyokimyasal ilişkileri öğrenmelerinin şart olmadığı bildiriliyor. Bonn Üniversitesi’nde yürütülen yeni bir çalışmada, bu modellerin sonuçları ağırlıkla benzerliklere ve istatistiksel korelasyonlara dayandırdığı ortaya kondu.
KARA KUTU SORUNU
Büyük dil modelleri matematik teoremlerinden müzik bestelemeye, reklam sloganlarından metin üretimine pek çok alanda şaşırtıcı başarılar sergiliyor. Ancak bu sonuçlara nasıl ulaşıldığı net değil. Bonn Üniversitesi Lamarr Makine Öğrenimi ve Yapay Zeka Enstitüsü’nden kimya bilişim uzmanları, ‘dil modellerinin kara kutu doğasına’ dikkat çekerek, özellikle dönüştürücü tabanlı CLM’lerin iç işleyişini aydınlatmaya odaklandı. CLM’ler, ChatGPT, Gemini veya Grok gibi modellerle benzer şekilde çalışsa da çok daha az veriyle eğitiliyor; bilgilerini SMILES dizileri gibi moleküler temsillerden ve yapı-ilişki kalıplarından ediniyor.
DİZİ TABANLI TASARIM
Farmasötik araştırmalarda hedef, belirli enzimleri inhibe eden ya da reseptörleri bloke eden maddeleri bulmak. CLM’ler, hedef proteinlerin amino asit dizilerine dayanarak aktif molekülleri tahmin etmekte kullanılıyor. Ekip, transformatörlerin tahmine nasıl ulaştığını anlamak için “dizi tabanlı moleküler tasarımı” test sistemi olarak seçti. Eğitimden sonra modele yeni bir enzim eklendiğinde, modelin onu inhibe edebilecek bir bileşik üretebildiği; ancak bunun, yapay zekanın inhibisyonun biyokimyasal prensiplerini öğrendiği anlamına gelmeyebileceği değerlendirildi.
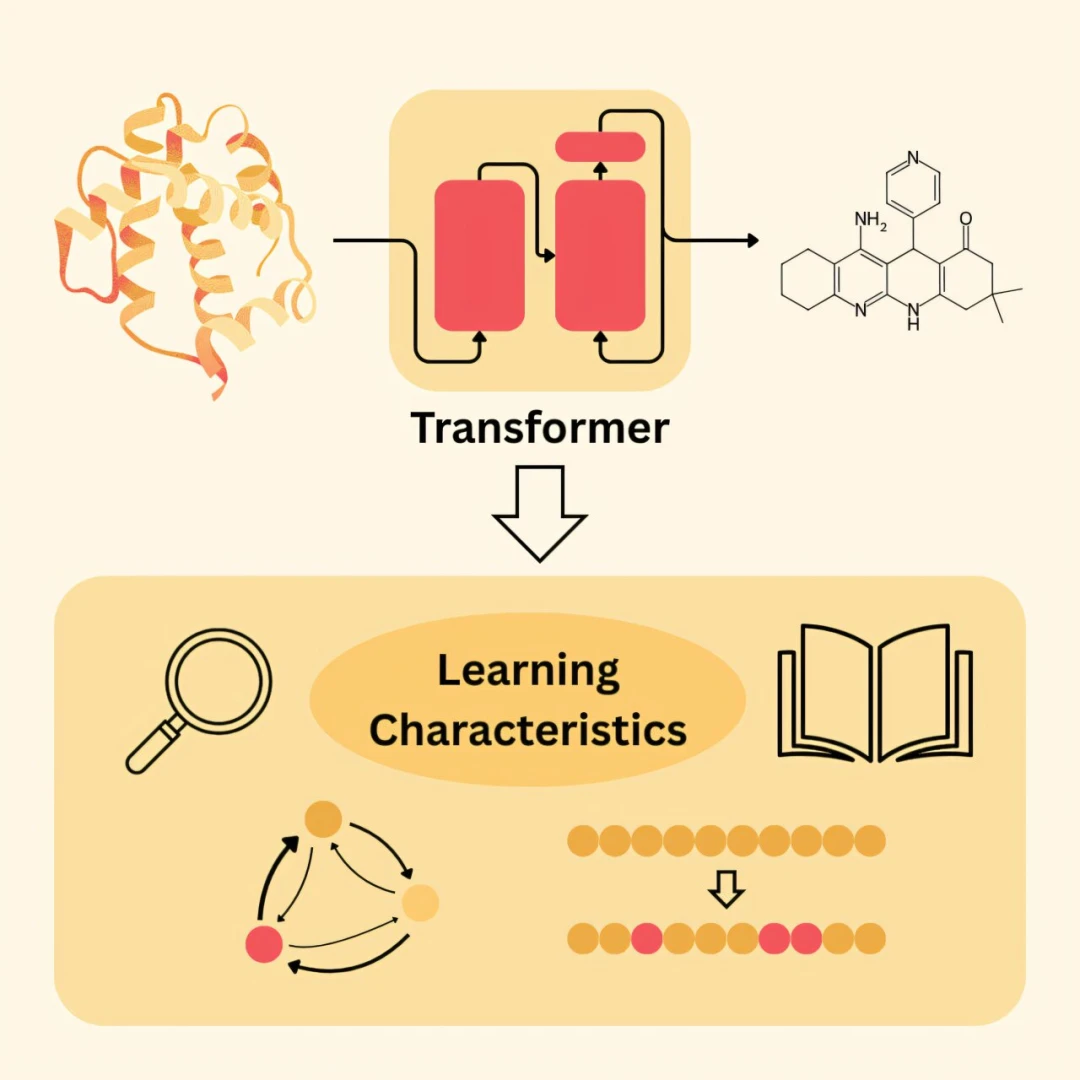
BENZERLİK ODAKLI ÇIKARIM
Araştırmacılar, eğitim verilerini sistematik biçimde değiştirerek modeli sınadı. İlk aşamada yalnızca belirli enzim aileleri ve inhibitörleri sağlandığında, aynı aileden yeni bir enzimle testte makul inhibitörler önerildi. Buna karşın, farklı aileden ve farklı biyolojik işleve sahip bir enzim kullanıldığında model doğru aktif bileşikleri tahmin edemedi. Bu bulgular, modelin genel geçer kimyasal prensipleri öğrenmediğini; önerilerin verilerdeki istatistiksel benzerliklere dayandığını gösterdi. Yani yeni enzim eğitim dizilerine benzerse, model benzer inhibitörleri ‘muhtemelen’ etkin kabul ediyor.
EŞİKLER VE KISITLAR
Modeller, amino asit dizilerinin yüzde 50–60’ı eşleştiğinde benzerlik varsayımıyla benzer inhibitörler önerecek şekilde çalıştı. Araştırmacılar, yeterli orijinal amino asit korunduğu sürece dizileri rastgele sıralayıp karıştırabildi ve model yine benzerlik kararı verdi. Oysa bir enzimin işlevini belirleyen çok spesifik bölgeler bulunuyor; tek bir amino asit değişikliği bile işlevi bozabiliyor. Buna rağmen modeller, işlevsel açıdan kritik ve önemsiz dizi kısımlarını ayırt etmeyi eğitim sürecinde öğrenemedi.
UYGULAMA VE YORUM
Sonuçlar, dizi tabanlı bileşik tasarımı için eğitilen dönüştürücü CLM’lerin, en azından bu test düzeneğinde, ‘derin bir kimyasal anlayıştan’ yoksun olduğunu ortaya koyuyor. Modeller, benzer bağlamlarda daha önce gördükleri bilgileri küçük değişikliklerle tekrar üretiyor. Bu durum, ilaç araştırmalarında kullanılmalarına engel değil, belirli reseptörleri bloke eden veya enzimleri inhibe eden molekülleri önerebilmeleri olası. Ancak bu başarı, kimyayı ‘anlamaktan’ değil, metin tabanlı moleküler temsillerdeki ve gözle görünmeyen istatistiksel korelasyonlardaki benzerlikleri yakalamaktan kaynaklanıyor. Dolayısıyla sonuçların değeri korunurken, aşırı yorumdan kaçınılması gerektiği vurgulanıyor.

Meta, sürekli kayıt alabilen 'süper algılama'lı yeni akıllı gözlükleri test ediyor

Avustralyalı ABC, haber üretiminde Claude yapay zekasını kullanacak

Yapay zeka iki yeni süperiletken malzemenin keşfini hızlandırdı

SpaceX, son altı ayda 260 Starlink uydusunu imha etti

Hayabusa2, 100 milyon km uzaktaki Torifune asteroitinin yakınından geçti

MeerKAT teleskobu 'Mavi Gözlü Pulsar'dan radyo sinyalleri yakaladı

Otonom sistemler için dünyanın ilk sertifikalı 3D ultrasonik sensörü tanıtıldı

Çin, ABD ambargolarını aşmak için 3D yığınlama teknolojisine yatırım yapıyor
Yorum yazmak için giriş yapın.
Yorumlar yükleniyor…